Wrong Question, Right Chip
What Auto China 2026, DeepSeek V4 and Tesla’s Q1 just quietly agreed on — and why the TOPS race is over.
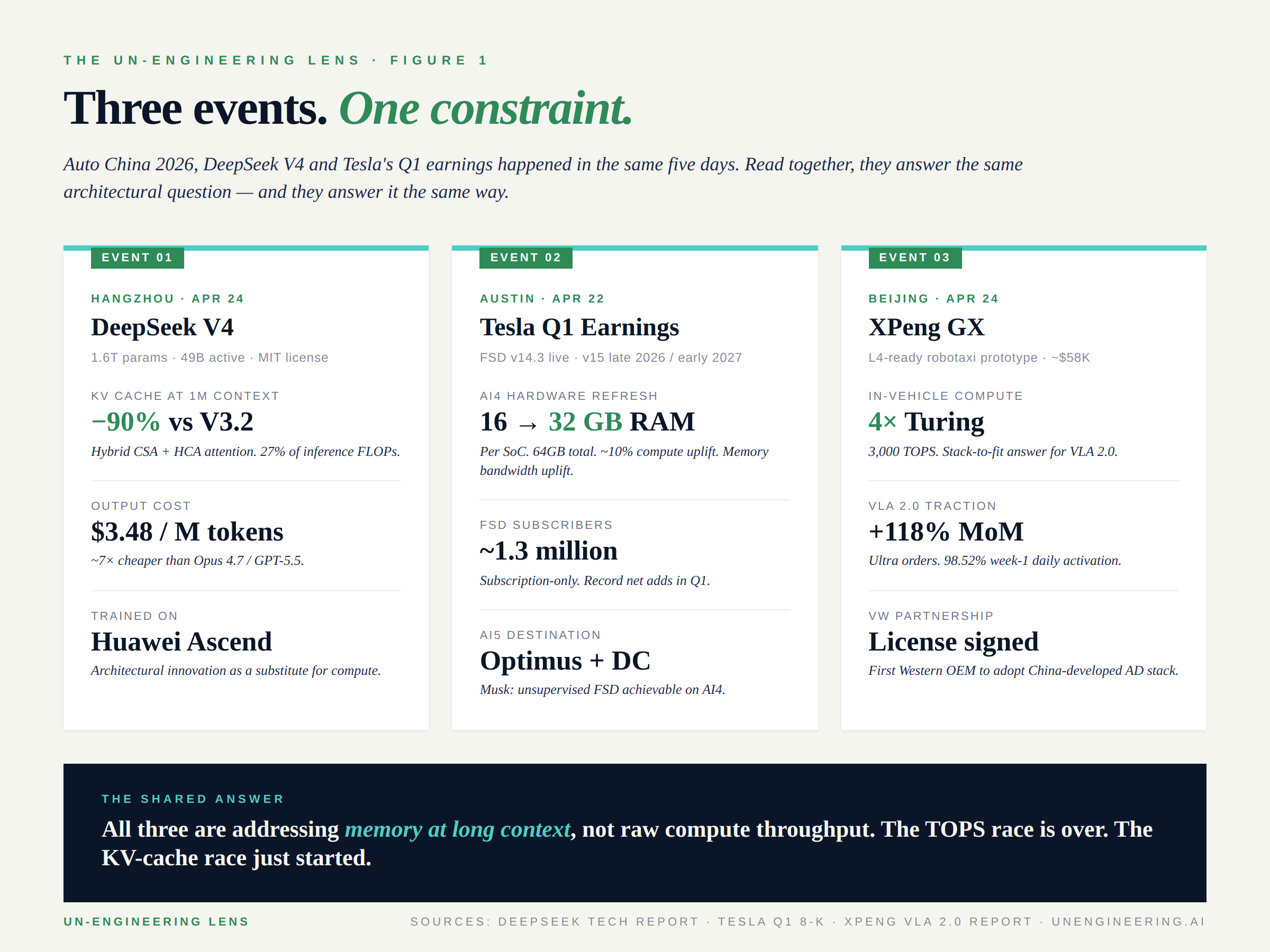
April 22–26, 2026 looked like three unrelated events.
Tesla reported Q1 earnings on Tuesday. DeepSeek dropped V4 on Hugging Face on Friday. Auto China 2026 opened in Beijing the same day and runs through May 3. Three different stages, three different audiences, three different stories.
Read them in sequence and they tell one story.
The industry has been asking the wrong question for eighteen months: whose AI is best? The right question — the one this week answered three different ways — is whose AI fits in the car? Not on a benchmark leaderboard. In the car. At fleet scale. At unit economics that work. With the deterministic guarantees a four-thousand-pound vehicle owes the road around it.
Every serious player who took the stage this week is independently converging on the same architectural answer. They are addressing memory at long context, not raw compute throughput. The TOPS race is over. The KV-cache race just started.
This is the lens I read the week through.
1. The DeepSeek V4 inflection
DeepSeek released V4-Pro and V4-Flash on April 24 under MIT license. The headline numbers are accurate but they are not the headline.
V4-Pro is a 1.6-trillion-parameter Mixture-of-Experts model with 49 billion parameters active per token. One million token context window. Trained on 32+ trillion tokens, on Huawei Ascend hardware. $1.74 per million input tokens, $3.48 per million output tokens — roughly seven times cheaper than Claude Opus 4.7 or GPT-5.5 at near-equivalent coding performance. V4-Flash drops to $0.28 per million output tokens. The economic story is real and the open-weights story is real.
Neither is the architecturally interesting story.
The architecturally interesting story is what DeepSeek did to attention. The model uses a hybrid mechanism that combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), interleaved across layers. CSA compresses key-value entries 4× along the sequence dimension and runs sparse selection over the compressed blocks. HCA compresses 128× and runs dense attention over the much shorter sequence. The result, at one-million-token context: 27% of the per-token inference FLOPs of V3.2. 10% of the KV cache. V4-Flash is more aggressive still — 7% of the KV cache vs V3.2.
That is not a marginal efficiency win. That is a fundamentally different cost profile at long context. And long context is precisely what Vision-Language-Action models for autonomous driving need: a vehicle is a long-running agent with thousands of perceptual frames, route history, prior maneuvers, and accumulated reasoning state — exactly the workload that breaks conventional attention’s quadratic cost.
DeepSeek did not write a paper about autonomy. They wrote a paper about how to fit long-context inference inside the silicon you already have.
That paper is now open-weight. Eight Chinese OEMs have already integrated DeepSeek family models. The architectural patterns will be in production VLA stacks within a year.
2. Tesla’s quiet RAM doubling
Tesla reported Q1 on April 22. The headline most outlets ran with was the 1.3 million paid Full Self-Driving subscribers — record net adds, FSD now subscription-only in most markets, V14.3 live since April. Those numbers are real and they matter.
The hardware story most outlets missed matters more.
Tesla announced an AI4 refresh, internally referred to as AI4+ or AI4.5. The compute uplift is modest — roughly 10% in trillions of operations per second. The memory uplift is the announcement. RAM doubles from 16GB to 32GB per system-on-chip. Each vehicle carries two SoCs, so 32GB to 64GB at the platform level. Memory bandwidth uplifts. Production target: mid-2027, gated by Samsung’s process modifications.
This is not a TOPS bet. It is a memory-bandwidth bet.
And then Musk said the line that should have been the headline. Asked about AI5 — the chip that just finished tape-out, that the team worked through holidays to ship — he said unsupervised FSD is achievable on AI4 hardware at “far greater than human” safety levels. AI5 is going into Optimus and the data center. Not immediately needed in the car.
Translation: Tesla just told the market that the bottleneck on FSD is not raw compute. It is memory. Every move on the hardware roadmap — RAM doubling, bandwidth uplift, V15’s "complete architectural overhaul" of the software stack targeted for late 2026 or early 2027 — is consistent with that read.
The same week DeepSeek showed the world how to attack KV cache architecturally, Tesla showed the world it’s attacking the same constraint with silicon. Two solutions. Same problem.
3. Auto China — the convergence
The Beijing International Automotive Exhibition opened on April 24 with 1,451 vehicles, 181 world premieres, and the most concentrated convergence of in-vehicle AI announcements I have read in a single week.
XPeng
XPeng showcased the GX, an L4-ready robotaxi prototype at roughly $58,000, built on four in-house Turing AI chips delivering 3,000 TOPS combined. VLA 2.0 — in production since March — is now showing the kind of conversion metrics no one in the West has reported: Ultra-series orders up 118% month-over-month, 98.52% week-one daily activation, 98% satisfaction across nearly 100,000 in-store demonstrations. Volkswagen has signed as the first Western OEM to license a China-developed AD stack. He Xiaopeng said the "DeepSeek moment" of autonomous driving had begun back in February. He repeated it more confidently in Beijing.
Huawei
Huawei unveiled ADS 5 the day before the show, positioning explicitly for L3 conditional autonomy with hands-off, eyes-off capability. The numbers Huawei put on the table reframe the supply-chain conversation: 60 EFLOPS of cloud training compute, up 21× in 29 months. $2.6 billion in 2026 R&D for autonomous driving alone. A $14.7 billion five-year compute investment plan that exceeds the combined AD R&D of every other major Chinese supplier. 25 OEM partners. 50+ models on the Qiankun platform. 10 billion cumulative kilometers of autonomous driving. Huawei is not playing the same game as Tesla or XPeng. It is playing the Tier-1-as-utility game — at hyperscaler economics.
Bosch
Bosch demonstrated Level 3 autonomy in production trim, currently testing on public roads in Wuxi under a license obtained in March. Notably, both BMW and Mercedes recently pulled back from L3 because of LiDAR and redundancy economics. Bosch is back in. The German Tier-1 with a Chinese deployment story is a structural shift.
Geely
Geely unveiled China’s first native robotaxi prototype — purpose-built rather than retrofit, Waymo-architecture-not-Cruise-architecture. Geely’s second-generation Galaxy Light concept added 2,160-line digital lidar and a 3,000+ TOPS compute platform. The robotaxi-as-product class just got serious.
Volkswagen
Volkswagen announced its "Agentic AI for all" roadmap built on the localized China Electronic Architecture (CEA). Twenty new electric vehicles in 2026 in China. CARIZON L2-NOA in production from 2026. CEA 2.0 in 2027 will integrate intelligent driving and cockpit into a unified system. VW has effectively conceded that the domestic Chinese AI stack is faster and cheaper than what Wolfsburg can build, and is now consuming it.
Five different bets. One shared architectural premise.
Long-context VLA inference, at the edge, with KV cache as the dominant constraint.
4. Three stacks, three scaling laws
The week’s announcements fall into three distinct stack architectures, each with a different scaling law and a different failure mode.
Tesla — vertical, closed. One fleet. One model. One chip lineage from HW3 through AI5. Roughly six billion cumulative FSD miles. 1.3 million paying customers. Stack ownership: 100%. The scaling law is simple: more cars equals more data equals better model equals more cars. The bottleneck is not technical — it is regulatory geography. Netherlands approval just landed; EU-wide rollout is pending Q2 regulatory cadence; China approval target is Q3. The data flywheel pauses at every border.
Huawei, Momenta, DeepRoute — horizontal, Tier-1. Many OEMs, shared stack, centralized cloud. The Huawei numbers above set the upper bound. DeepRoute reports 300,000 vehicles equipped today and a target of 1.3 million by end of year. Momenta is co-developing with BMW for the Neue Klasse line. The scaling law is fan-out: one stack across many OEMs, with cloud-side training as the moat. The bottleneck is downstream differentiation. If 25 OEMs ship the same Huawei perception stack, the OEM is the sheet-metal vendor. Brand-level distinction collapses upstream into the Tier-1.
XPeng — vertical-but-licensed. Own chip. Own model. Sell to Volkswagen. The scaling law combines vertical integration with horizontal monetization, and it is the most capital-intensive of the three. XPeng is simultaneously running a chip program (Turing), a foundation-model program (VLA 2.0 across cars, robotaxis, humanoids, and flying cars), a robotics program (IRON), and an aviation program (Land Aircraft Carrier). The bottleneck is sustained capital across more than one cycle.
All three are placing the same architectural bet. They scale, monetize, and break in completely different ways.

5. What nobody announced
Two structural gaps remained unaddressed across the entire week. Both sit at the heart of why "AI in the car" is not the same problem as "AI on a server." Neither showed up on any stage in Beijing.
Mixed-criticality co-residency. ASIL B/D safety-critical workloads alongside best-effort microservices on a shared hypervisor — with guaranteed worst-case execution time per application — remains unsolved at platform level. The TOPS-first conversation has not engaged with deterministic scheduling. The unified-OS conversations (VW’s CEA, Tesla’s V15 overhaul, the various OEM "vehicle OS" announcements) are architecturally silent on it. Bosch’s L3 system in Wuxi is the closest answer in production, but it sits in a separate compute domain — not co-resident with infotainment, agentic AI, or VLA inference. Apollo Go’s Wuhan fleet freeze last quarter was a resilience failure, not a perception failure. Mixed-criticality is the architectural answer the industry keeps not talking about.
Network-centric compute as a first-class scheduling primitive. DeepSeek V4’s KV-cache compression makes long-context inference economically deployable for the first time. None of the announcements treat the network as inference fabric. Tesla’s stack is connectivity-blind by design. Every Auto China platform schedules workloads device-only — even though the bursty, latency-tolerant tail of agentic VLA reasoning is exactly what 5G-Advanced edge MEC was built for. A one-million-token context window does not have to live in the SoC. The car needs deterministic on-device inference; the cloud-scale agentic tail can offload — if the scheduler treats network as a tier. None of the platforms announced this week treat it that way.
These are the two architectural questions that actually decide whether AI ships in vehicles at fleet scale, with the unit economics that work, with the deterministic guarantees the road requires. Both are still open.

Closing
The headline of April 22–26 was not "DeepSeek beats Anthropic." It was not "XPeng challenges Tesla." It was not "Bosch finally ships L3."
The headline was that every serious player — across geographies, ownership models, and announcement formats — independently concluded the same thing about the architecture of Physical AI. They announced it through different lenses. The TOPS race is over. The KV-cache race just started.
And the gating question for the next eighteen months is not whose model wins on benchmarks. It is whose model fits in the car — at fleet scale, at unit economics that work, with the deterministic guarantees a four-thousand-pound vehicle owes the road around it.
That is the question this week’s three memos answered together.
It is the question worth building toward.
THE UN-ENGINEERING LENS reads what the announcements don’t say.



