Why the Smartest Robot Is the One That Doesn’t Carry Its Own Brain
The prevailing blueprint for building an autonomous mobile robot is deceptively simple: pack the most powerful AI computer you can into the chassis, wire every sensor into it, run inference locally, and hope the battery lasts long enough to justify the engineering. Tesla’s Optimus humanoid is the poster child of this philosophy—its custom AI4 silicon sits inside the torso, consuming substantial power to crunch multi-modal perception and real-time motion planning, all while sharing a finite battery with 28 structural actuators and over 40 sensors.
It is brilliant engineering. It is also, I believe, the wrong long-term architecture for the vast majority of Physical AI applications—from warehouse logistics and agricultural autonomy to healthcare assistants and last-mile delivery robots.
There is a better path. Advances in 5G Advanced (3GPP Release 17 and 18) and the emerging 6G research framework now make it feasible to fundamentally disaggregate the robot’s compute stack from its mechanical platform, offloading the heaviest AI workloads to permanently powered edge infrastructure with GPU acceleration. The result is a lighter, cheaper, longer-running robot that is paradoxically smarter and safer than its self-contained alternative.
I call this approach “un-engineering” Physical AI—not because it requires less engineering, but because it inverts the traditional design assumption that intelligence must be co-located with actuation.
The Monolithic Trap: Why Onboard-Everything Doesn’t Scale
Today’s autonomous robots face a brutal energy equation. High-resolution LiDAR, stereo camera arrays, IMUs, ToF depth sensors, and force-torque sensors generate data rates that can exceed 10–20 Gbps in aggregate. Processing that data through transformer-based perception models, occupancy networks, and real-time path planners demands GPU-class silicon drawing 50–200 watts or more. In a battery-powered form factor, this compute load can consume 30–50% of the total energy budget—directly halving operational runtime.
Tesla addresses this by designing custom silicon (AI4) optimized for power efficiency. That is a valid strategy when you are Tesla—when you own the fab relationship, the training cluster, and the deployment fleet. But for the broader Physical AI ecosystem—the thousands of robotics companies building for logistics, inspection, agriculture, surgery assistance, and eldercare—the monolithic onboard-compute model creates three compounding problems:
• Thermal and power constraints limit the AI silicon you can actually deploy, forcing painful tradeoffs between model complexity and battery life.
• Hardware-software coupling means every HPC upgrade requires a full mechanical re-integration, slowing the pace of AI improvement to the pace of physical product cycles.
• Data stays trapped on the device. Rich sensor streams are reduced to inferences onboard and discarded. The raw data that would fuel a learning flywheel—continuous model retraining, fleet-wide anomaly detection, digital twin construction—never leaves the chassis.
The question is not whether onboard AI works. It clearly does. The question is whether it is the most scalable, safe, and economically efficient architecture when the network can now do something it could not do five years ago.
The 5G Advanced / 6G Inflection: From Connectivity to Compute Fabric
3GPP Release 17 and 18 introduce capabilities that transform 5G from a communications pipe into a deterministic, low-latency compute fabric purpose-built for cyber-physical systems:
• URLLC enhancements (Rel-17) push round-trip latency below 5 ms with 99.9999% reliability over private network deployments—well within the control-loop requirements of most mobile robot actuators.
• NR sidelink and Reduced Capability (RedCap) devices (Rel-17/18) enable a tiered architecture: high-bandwidth uplink for sensor offload alongside lightweight sidelink for peer-to-peer robot coordination.
• AI/ML-native air interface (Rel-18) introduces network-side intelligence for beam management, channel estimation, and predictive resource allocation—critical for maintaining quality-of-service as robots move through complex indoor environments.
• Emerging 6G research targets sub-millisecond latency, integrated sensing and communication (ISAC), and native digital-twin support—pushing the architecture toward real-time, network-hosted perception.
Critically, these advances coincide with the maturation of AI RAN solutions: GPU-accelerated edge compute co-located at the radio access point. Instead of a dumb base station and a distant cloud, the edge node itself becomes a high-performance inference engine with permanent power, liquid cooling, and virtually unlimited energy—everything the robot lacks.
The Architecture: Signal-to-Service Disaggregation with L1 Hypervisor Safety
The proposed design is a clean separation of concerns between the robot and the network:
On the Robot (the “Thin Client”)
The onboard HPC runs a Type-1 (bare-metal) hypervisor—such as a safety-certified L1 hypervisor like those used in automotive-grade systems (e.g., QNX Hypervisor, ACRN, or PikeOS)—that fully virtualizes the compute environment into isolated partitions. One partition handles the safety-critical actuation kernel (real-time motor control, emergency stop logic, and the failsafe state machine) at the highest ASIL or SIL rating. Another partition manages the 5G modem stack and sensor data marshalling. A third, lower-criticality partition runs application-level orchestration.
This signal-to-service embedded architecture means sensor data is captured, time-stamped, and streamed to the network with minimal onboard processing. The robot retains only what it needs for real-time reflexive safety—collision avoidance at the actuator level, emergency braking, and connectivity-loss fallback—while offloading perception, planning, and higher-order reasoning to the edge.
At the Edge (the “Network Brain”)
The GPU-accelerated AI RAN edge node receives the full-fidelity sensor stream, runs foundation-model inference (3D scene understanding, semantic mapping, task planning), and returns actuation commands back to the robot over the deterministic 5G link. Because the edge has permanent grid power and active cooling, it can run models that would be thermally and energetically impossible onboard. It can also run multiple robot instances concurrently—a single edge cluster can serve a fleet, amortizing GPU cost across dozens of machines.
The Battery Dividend: Lighter, Longer, Cheaper
This is the twist that changes the economics. By moving the 50–200W GPU compute load off the robot and onto the permanently powered edge, the robot’s electrical budget drops dramatically. In a typical 1–2 kWh mobile robot battery, eliminating onboard AI compute can extend operational runtime by 40–60% or equivalently allow engineers to shrink the battery by a third—reducing weight, cost, and charge time simultaneously. Lighter robots need smaller actuators, which consume less power, creating a virtuous cycle.
The 5G modem itself draws only 3–8 watts—a fraction of what it replaces. The net energy math is overwhelmingly in favor of offload.
Functional Safety Without Compromise
The obvious objection is: what happens when the network goes down?
This is where the L1 hypervisor architecture proves its worth. The safety-critical partition running on the onboard HPC is entirely independent of the network path. It continuously monitors connectivity health and operates a deterministic failsafe state machine—directly analogous to the safe-stop architecture mandated for autonomous vehicles under ISO 26262 and ISO 22737.
On loss of connectivity, the robot transitions gracefully: it decelerates, signals its status, and navigates to a safe standby position—moving aside, stopping in a designated zone, or holding its last known safe pose. This is not a crash. It is an engineered degradation, validated and certified to the same functional safety standards (up to SIL 3 / ASIL D) that govern the actuation layer. The robot never depends on the network for safety. It depends on the network for intelligence.
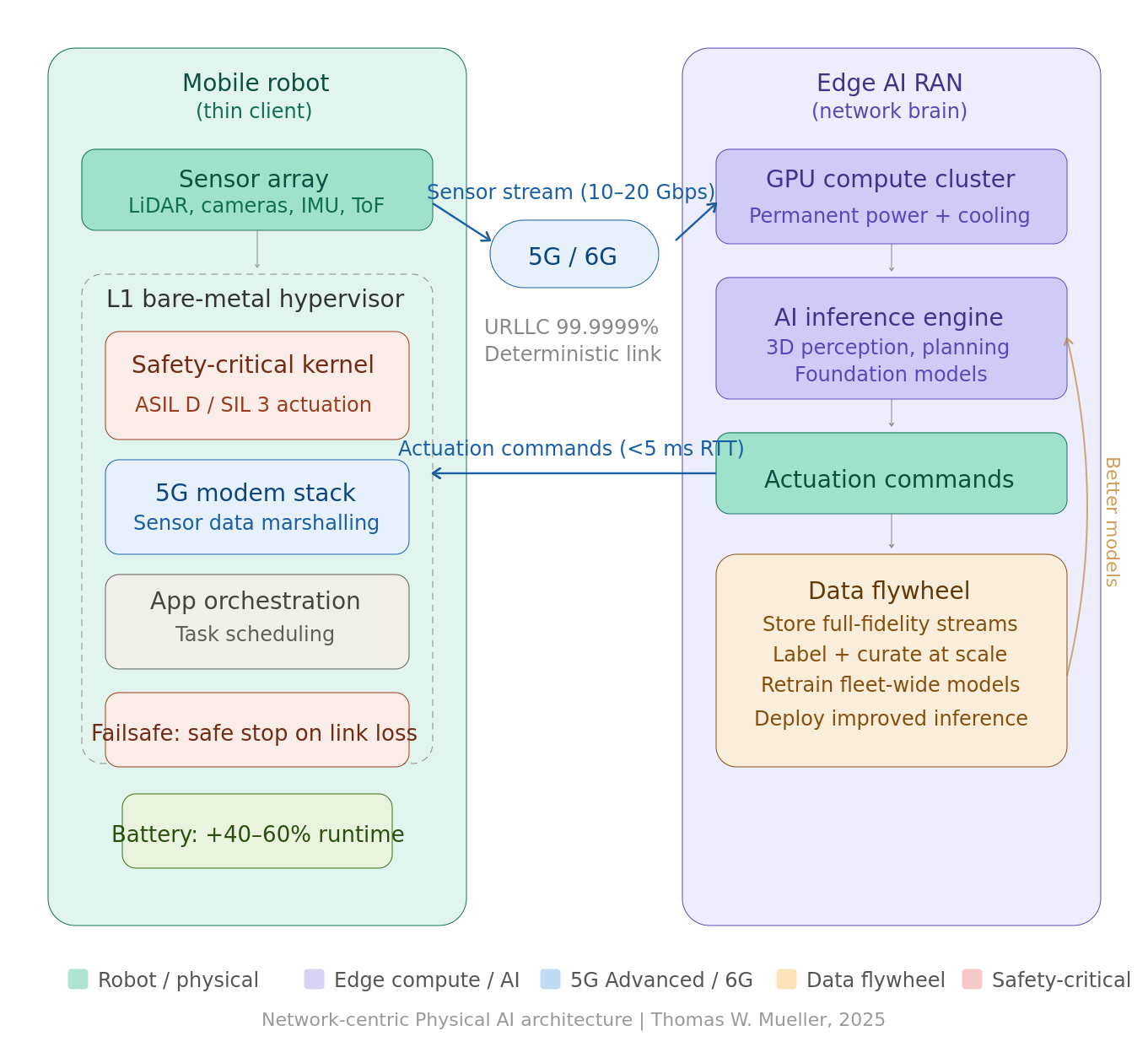
The Data Flywheel: From Byproduct to Strategic Asset
In an onboard-compute architecture, raw sensor data is an inconvenience—something to be processed and discarded as fast as possible to conserve storage and power. In the network-centric architecture, raw sensor data becomes the primary strategic asset.
Because full-fidelity LiDAR point clouds, camera feeds, and force-torque telemetry are already streaming to the edge, they can be simultaneously ingested into a data harvesting pipeline—stored, labeled, curated, and fed back into model retraining loops. This creates a data flywheel that accelerates with every operational hour across the fleet: more data yields better models, better models yield more precise actuation, more precise actuation enables more complex tasks, which generate richer training data.
This flywheel is extremely difficult to build in an onboard-only architecture. The bandwidth bottleneck of periodic uploads, the storage limitations of embedded systems, and the computational cost of on-device data curation all conspire against it. The network-centric design makes it native.
Why This Matters Now
We are at an inflection point. The Physical AI market is projected to exceed $20 billion by 2030, and thousands of companies are designing the robot architectures that will define the next decade. The decisions being made today—where to place compute, how to partition safety, how to handle data—will compound for years.
Tesla can afford to put a custom AI supercomputer inside every humanoid because Tesla is simultaneously the chip designer, the car company, and the AI lab. For everyone else, the smarter play is to let the network carry the cognitive load and engineer the robot for what it does best: sensing, moving, and operating safely in the physical world.
The ingredients are finally here. 5G Advanced gives us the deterministic latency and reliability. AI RAN gives us GPU-accelerated edge compute at the radio site. L1 hypervisors give us certified functional safety partitioning. And the economics are compelling—longer battery life, lower BOM cost, faster AI iteration, and a data flywheel that no onboard architecture can match.
It is time to un-engineer the robot—and let the network be its brain.



