The Day the Robotaxis Froze:
A Four-Layer Resilience Architecture for Autonomous Fleets
On the evening of March 31, 2026, over 100 Baidu Apollo Go robotaxis simultaneously froze on the elevated expressways of Wuhan, a city of 14 million. Vehicles halted in fast lanes with traffic streaming past. In-car SOS buttons failed. One passenger waited 90 minutes for help that never came. A month earlier, Waymo’s fleet gridlocked San Francisco during a power blackout when cellular networks collapsed and vehicles could not reach remote assistance servers for confirmation checks.
These are not edge cases. They are architectural failure modes now manifesting at fleet scale. And they expose a truth the industry has been slow to confront: the dominant robotaxi architecture—centralized cloud brain, single-carrier cellular link, limited onboard fallback—is itself a single point of failure.
The Common Architecture—and Its Fatal Assumption
Most commercial robotaxi operators—Baidu, Waymo, Pony.ai—rely on a shared architectural pattern: an onboard perception and driving stack that depends on continuous cloud connectivity for fleet management, routing, remote assistance, and in many cases, planning confirmation. This architecture assumes three things that the Wuhan and San Francisco incidents have proven wrong: that the cloud will always be reachable, that the cellular link will always be available, and that the onboard system can execute a safe stop when both fail.
In Wuhan, the vehicles did not pull over. They stopped in place—some in the fast lane of elevated highways. The “safe stop” mechanism that should have moved vehicles to the shoulder either was not implemented, was not triggered correctly, or the system’s failure mode was so total that even the safety fallback was unreachable. That is an ASIL-D violation in automotive safety terms: a loss of the entire safety function during a hazardous operating condition.
Waymo’s December 2025 San Francisco incident was subtler but equally revealing. The company’s vehicles are designed to occasionally request “confirmation checks” from remote human operators before proceeding through complex intersections. When the city-wide blackout took down traffic lights and the cellular network simultaneously, hundreds of vehicles queued for a remote confirmation that could not be delivered. The result was fleet-wide gridlock—not from a software bug, but from an architecture that made a non-safety-critical function (remote confirmation) into a blocking dependency.
A Four-Layer Defense Architecture
The engineering response must be layered. No single redundancy mechanism is sufficient. What follows is a four-layer resilience framework that, if adopted, would have prevented both the Wuhan freeze and the San Francisco gridlock.
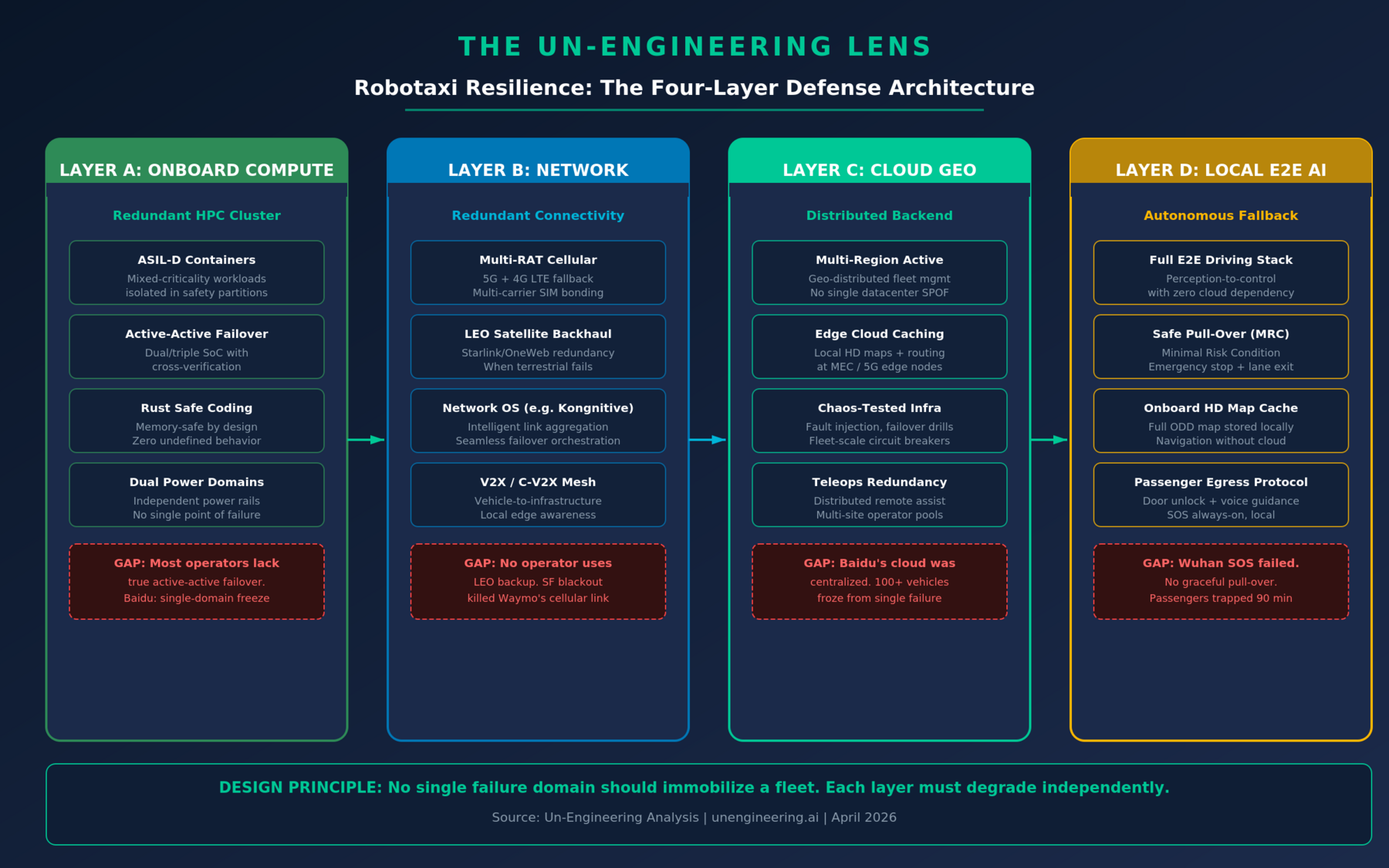
Layer A: Redundant Onboard Compute with ASIL-D Containers
The onboard compute must run in an active-active failover configuration across a cluster of high-performance computing units. Mixed-criticality workloads—perception (safety-critical), infotainment (non-critical), fleet telemetry (operational)—must be isolated in ASIL-D rated containers with deterministic scheduling. If one compute domain fails, the other continues driving without interruption.
Zoox is the only operator that comes close to this today, with mirrored logic domains and cross-verification on its NVIDIA-powered compute platform. Tesla’s HW4.5 introduces a third SoC—a step toward compute redundancy, though Tesla has not disclosed whether it supports true active-active driving failover or merely load distribution. Baidu’s architecture, based on the Wuhan evidence, lacked this entirely: a single system malfunction took out the entire driving function across the fleet.
The coding stack matters too. Safety-critical driving software written in Rust eliminates entire categories of memory-safety vulnerabilities—buffer overflows, use-after-free, data races—that C/C++ stacks are perpetually exposed to. In an ASIL-D context, memory-safe-by-design is not a preference; it is a requirement for the level of determinism these systems demand.
Layer B: Redundant Wireless Connectivity with Network OS
No current robotaxi operator uses LEO satellite backhaul as a redundant connectivity path. This is the most glaring gap in the industry. When the San Francisco blackout killed cellular towers, Waymo’s vehicles had zero alternative uplinks. A network operating system—such as Kongnitive.net or equivalent—that bonds multiple radio access technologies (5G, 4G LTE, Wi-Fi, LEO satellite) and orchestrates seamless failover would have kept the cloud link alive.
Multi-carrier SIM bonding across at least two cellular networks, combined with a Starlink or OneWeb LEO terminal as the path of last resort, creates a connectivity stack where no single terrestrial failure can sever the vehicle-to-cloud link. The network OS layer is critical: it must detect link degradation in milliseconds, reroute traffic, and maintain session continuity for the fleet management and teleoperation streams without driver-visible interruption.
Layer C: Geo-Distributed Cloud with Fleet-Scale Circuit Breakers
Baidu’s Wuhan failure has all the hallmarks of a centralized cloud single point of failure—one malfunction propagated simultaneously to over 100 vehicles. The backend must be geo-distributed across multiple regions with active-active replication, edge caching of HD maps and routing data at 5G MEC nodes, and fleet-scale circuit breakers that prevent a backend fault from cascading to the entire fleet.
Mobileye’s “fast-think, slow-think” architecture represents a meaningful step: safety-critical perception runs onboard at 10 Hz, while deeper planning and reasoning calls are offloaded to cloud-based vision-language models at lower frequency. This design inherently degrades gracefully—if the cloud is unreachable, the vehicle continues driving on its fast-think stack. Every operator should adopt this principle.
Layer D: Fully Local E2E AI Driving Stack with Emergency Pull-Over
The ultimate fallback is a fully self-contained, onboard end-to-end AI driving stack that requires zero offboard functions for perception, planning, or control. Tesla’s architecture is arguably closest to this model: its FSD neural network runs entirely on-vehicle, trained on billions of miles of fleet data, with no dependency on cloud-based planning or remote confirmation for the core driving task. This is why Tesla vehicles navigated the San Francisco blackout while Waymo’s fleet froze.
But local autonomy alone is not enough. The vehicle must also implement a Minimal Risk Condition (MRC)—the ability to safely pull over to the shoulder, activate hazards, unlock doors, and provide voice guidance to passengers—all without cloud connectivity. In Wuhan, the SOS system itself failed. Passengers were trapped for up to two hours. This is unacceptable. The MRC must be a hardwired, locally-executed function that cannot be disabled by any upstream system failure.
Operator Architecture Gap Analysis
Mapping the current operator landscape against the four-layer framework reveals significant gaps across the industry.

Baidu Apollo Go is the most exposed. The Wuhan incident demonstrated failures across all four layers simultaneously—no compute redundancy to keep driving, no network backup, a centralized cloud that propagated a single fault fleet-wide, and no local MRC to pull vehicles safely to the shoulder.
Waymo has strong onboard compute with its 6th-generation Driver stack, but its dependency on remote confirmation checks and single-carrier cellular creates a blocking vulnerability exposed in the San Francisco blackout. The disclosure that remote assistance workers are based in the Philippines adds geopolitical and latency risk to the teleoperations layer.
Tesla benefits from the most cloud-independent driving stack in the industry—its end-to-end neural network runs entirely onboard. However, its HW4 platform lacks the dual-redundant power supplies and ASIL-D containerization that regulators will increasingly require for true L4 certification. The Cybercab, with AI5 and purpose-built safety architecture, may close this gap.
Zoox has the most safety-forward architecture among current operators: purpose-built vehicle with mirrored compute domains, redundant hardware throughout, and no single point of failure as a design principle. Its NVIDIA-powered platform and Amazon’s cloud infrastructure give it strong positions across Layers A and C. The remaining question is whether its network connectivity layer includes LEO redundancy.
MOIA/Mobileye (VW ID.Buzz) brings Mobileye’s dual-path sensor fusion—independent camera and radar-lidar perception systems—and the Responsibility-Sensitive Safety (RSS) model for mathematically verifiable safe behavior. The fast-think/slow-think cloud architecture is the right design pattern. But MOIA is pre-commercial, with safety driver removal targeted for 2026 and limited real-world incident data. The ambition of 100,000 vehicles by 2033 will require proving this architecture at Wuhan-like scale.
Pony.ai has built a solid onboard stack with ISO 26262 compliance, NVIDIA Orin compute, and a 7th-generation ADK with 100% automotive-grade components. Its partnership with Tencent Cloud raises the same centralization concerns as Baidu’s architecture. The Beijing fire incident in May 2025 and one remote monitor per 12 vehicles ratio suggest the teleoperations layer is stretched thin.
Lucid-Nuro-Uber enters with perhaps the most modern hardware foundation: NVIDIA DRIVE AGX Thor on the Hyperion platform, Nuro’s end-to-end AI foundation model with verifiable safety logic, and Uber’s massive operational infrastructure. With 20,000 vehicles planned and a Bay Area launch in late 2026, this consortium has the opportunity to design the four-layer architecture from day one rather than retrofit it after a fleet-scale incident.
The Engineering Imperative
Wuhan was not a black swan. It was an inevitable consequence of architectures designed for the happy path. The robotaxi industry is scaling at extraordinary speed—Waymo now delivers 500,000 paid rides per week and targets one million by year-end. Baidu operates over 1,000 vehicles in a single city. Tesla is expanding unsupervised FSD across Austin. At this scale, a centralized cloud failure does not strand a vehicle. It paralyzes a city.
The four-layer resilience architecture—redundant onboard compute with ASIL-D containers and memory-safe code, redundant multi-path wireless with LEO backup and intelligent network OS, geo-distributed cloud with edge caching and circuit breakers, and a fully local E2E driving stack with hardwired emergency pull-over—is not aspirational. Every component exists today. The engineering challenge is integration, certification, and the organizational will to treat resilience as a first-class design requirement rather than an afterthought.
The next fleet-scale failure is not a question of if, but when. The only question is whether operators will have built the architecture to survive it.



