The Robot Is Not the Unit of Compute
Why thin robots, sovereign fleet inference, and private 5G-Advanced — not bigger on-board VLA models — will define the next phase of Physical AI.
A first-principles look at the most expensive architectural assumption in humanoid robotics — and why the DRAM super-cycle just made it untenable.
I spent the weekend watching ninety minutes of humanoid-robot demos compiled into a single industry sizzle reel. Unitree’s G1 walking 130,000 steps in −47°C cold. Boston Dynamics’ Atlas at 56 degrees of freedom moving from research prototype to Hyundai’s shop floor. Figure 03 doing pick-and-place in real American homes. AgiBot doing kung fu. LimX shipping 18 humanoids that coordinate themselves under their KOSA cognitive operating system. EU Robot Technology in Shanghai opening the world’s first 100,000-units-a-year humanoid joint factory. Unitree pricing the R1 at $4,370. Faraday Future entering with an open-source ecosystem from $2,499. Karol Hausman and the Physical Intelligence team — of π0 and π0.5 fame — calling this the “GPT-2 moment” of robotics.
The footage is genuinely impressive. The mechatronics are extraordinary. The supply-chain integration in China is, frankly, decisive. And yet, watching all of it back-to-back, I kept arriving at the same uncomfortable thought:
“Almost everyone in this industry is building the wrong thing.”
Not the wrong robot. Not the wrong actuators. The wrong unit of compute.
What the industry has already decided
Look across the demos and a single architectural premise repeats itself. The robot is a self-contained AI appliance. It carries its own perception stack, its own planner, its own Vision-Language-Action model, its own LiDAR fusion, its own batteries, its own thermal solution, and increasingly its own multi-billion-parameter foundation model. Tesla’s Optimus carries an FSD-class compute. Figure 03 carries Helix. Boston Dynamics’ Atlas carries dual high-performance SoCs feeding a learned policy. Unitree’s G1 carries 23–43 motors, 3D LiDAR, depth cameras, and an on-board inference stack rated for two hours of operation on a quick-swap battery.
The trajectory is unambiguous. As VLA models scale — Physical Intelligence’s π series, Google’s Gemini Robotics, NVIDIA’s GR00T, Figure’s Helix, every Chinese equivalent now in flight — the on-robot memory and compute requirement is exploding. Every BOM I have looked at in the last twelve months allocates more silicon, more memory, more cooling, and more battery to the brain inside the robot. The bigger the model, the heavier the appliance.
This is the consensus. This is also, in my view, an unforced strategic error.
The memory bomb that just landed
Three weeks ago, TrendForce published its Q1 2026 contract-price data for DRAM. The numbers are not subtle:
→ DRAM contract prices surged 90–95% quarter-over-quarter in Q1 2026, the steepest move on record.
→ A further 58–63% increase is forecast for Q2 2026, with mobile LPDDR5 modules projected at $19.30–19.80 per gigabyte by end of quarter — a price point that simply did not exist on any consumer roadmap twelve months ago.
→ LPDDR5 contract prices have tripled since Q1 2025 already. Counterpoint and IDC both expect DRAM supply growth in 2026 to land near 16%, against demand growth around 35%. SK Hynix is sold out on HBM, DRAM, and NAND through 2026.
→ This is not a transient. It is what analysts are now publicly calling a structural super-cycle, expected to persist into 2027 as wafer capacity gets reallocated to high-bandwidth memory for AI accelerators — three times the wafer area per bit of standard DRAM.
Now drop that into a humanoid BOM. The Hyundai Lesson — which we covered in an earlier Lens — told us that actuators are roughly sixty percent of a humanoid’s bill of materials, and that the East Asian supply-chain integration around joint motors is the single largest cost advantage in the industry. Compute, memory, sensors, and battery have historically sat somewhere around fifteen to twenty percent of BOM. With an LPDDR5X price multiple of five to six over eighteen months, and on-robot VLA model footprints climbing from sub-billion parameters into the three-to-seven-billion-parameter range, that fifteen-percent line is on track to become twenty-five-to-thirty percent. The R1 priced at $4,370 today may not be priceable at $4,370 in twenty-four months. Nobody I have spoken to in OEM procurement has fully written this through their 2027 BOM.
Every wafer reallocated to HBM for an NVIDIA accelerator is a wafer denied to the LPDDR5X module of the humanoid we were planning to ship at scale.
Wrong question, right question
There is a debate worth having about how to keep on-robot VLA models running once memory is no longer cheap. Quantize. Distil. Prune. Move to lower-precision compute. All real, all useful, all incremental. But the more useful question is one register higher:
|
WRONG QUESTION How do we cram bigger VLA
models onto humanoid robots in 2027? |
|
RIGHT QUESTION Why is the robot the unit
of compute? What if the robot is a sensor-actuator endpoint and the brain is
a sovereign fleet service? |
This is the thin robot thesis. And it sits at the centre of an architectural reframing the industry has not yet done.
The thin robot, formally
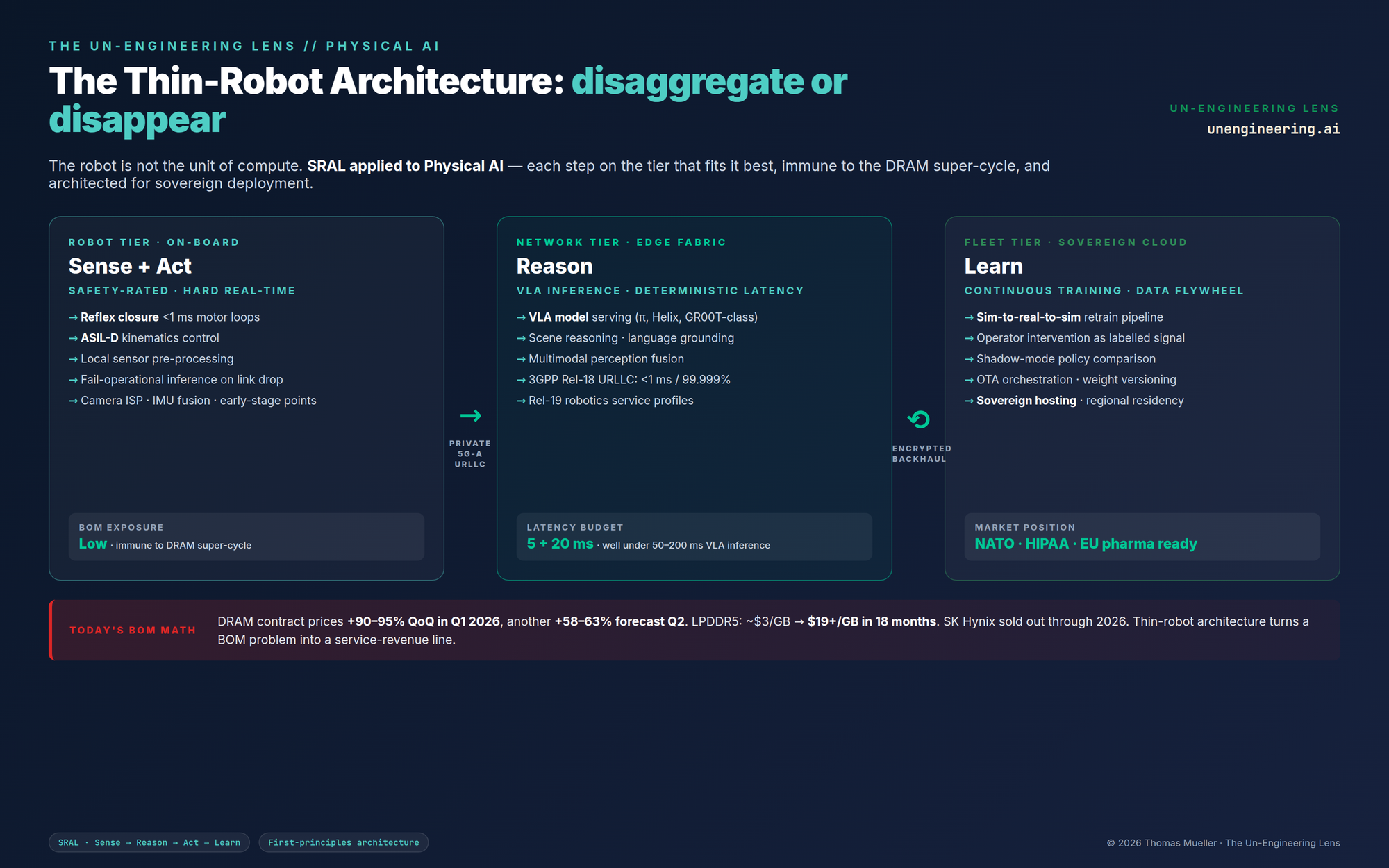
Long-time readers of this Lens will recognise the underlying pattern. I have argued before that mature stacks disaggregate. ADAS still has not, which is one reason almost no Western OEM’s ADAS gets better between releases. Software-Defined Vehicles are slowly disaggregating, which is why AI-Defined Vehicles will overtake them. Humanoids are at the same fork in the road, twelve to eighteen months earlier. The cleanest disaggregation in Physical AI maps directly onto the SRAL framework — Sense, Reason, Act, Learn — with each step on the architectural tier that fits it best:
|
ROBOT TIER Sense + Act Safety-rated
reflexes. Hard real-time motor loops (<1 ms). Local sensor fusion. ASIL-D
kinematics. Modest compute, modest memory, modest BOM exposure to DRAM
prices. |
|
NETWORK TIER Reason VLA inference.
Scene reasoning. Language grounding. Multimodal perception. Private
5G-Advanced URLLC <1 ms today; 6G ULL pending. Robot becomes a wireless
thin client. |
|
FLEET TIER Learn Continuous
training. Data flywheel. Sim-to-real-to-sim. OTA orchestration. Sovereign
hosting. Encrypted weights. Regional residency. |
Robot tier: just enough to stay alive
The on-robot stack collapses to what the safety case actually requires. Hard real-time motor control. Sub-millisecond reflex closure for collision avoidance, stability, and emergency stop. Local sensor pre-processing at the edge of each sensor (camera ISP, IMU fusion, radar/lidar early-stage points). A small, safety-rated inference engine for fail-operational behaviours when the link to the network drops. ASIL-D class compute for kinematics. None of this requires a five-billion-parameter VLA. None of this requires thirty-two gigabytes of LPDDR5X. The robot becomes radically cheaper to manufacture, far easier to certify, and immune to memory super-cycles.
Network tier: where reasoning actually lives
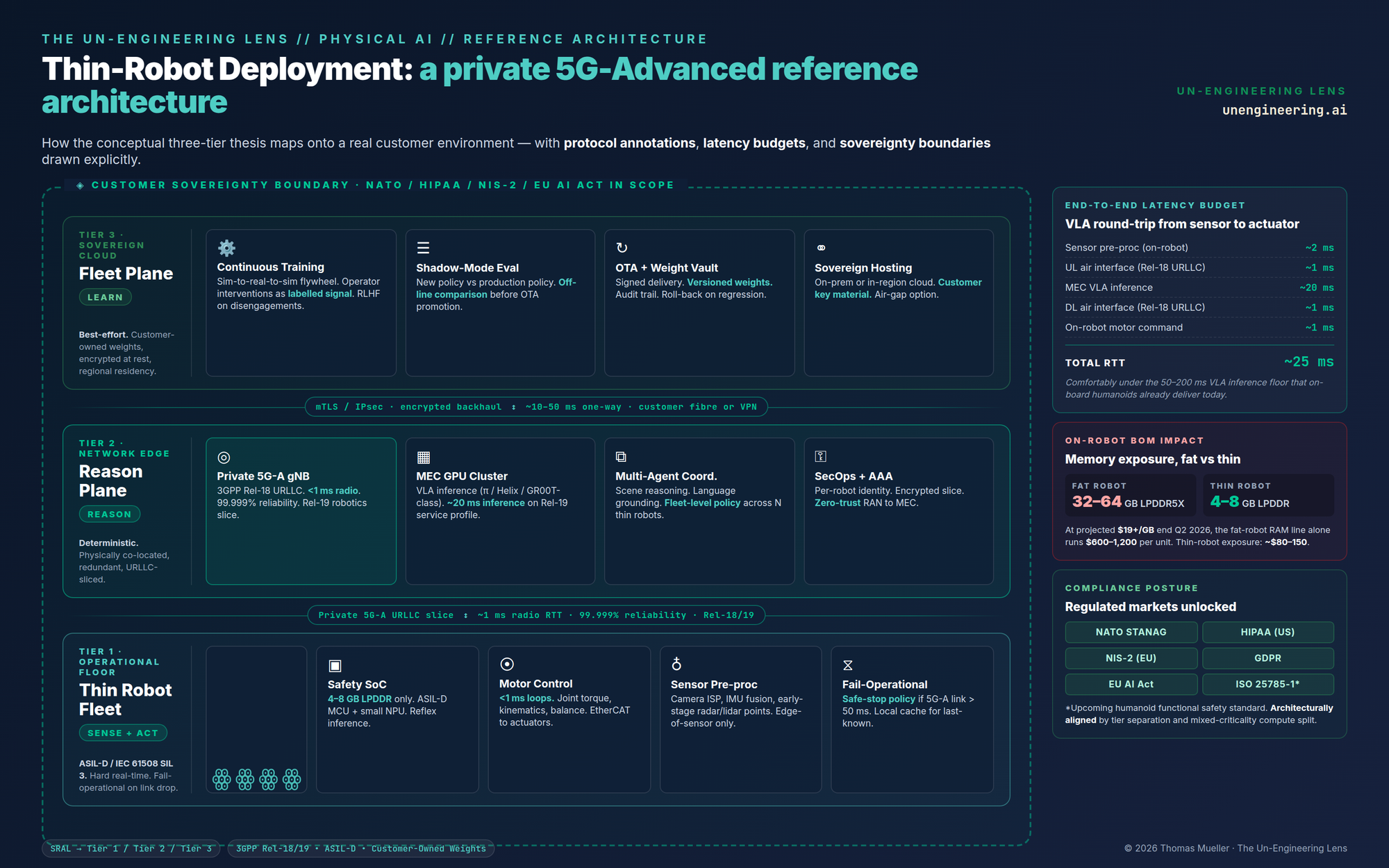
Reason — the heavy lift — moves off the robot and onto a private network compute fabric. This is the part of the architecture that has only become feasible in the last twenty-four months and is poorly understood outside telco-robotics intersections. 3GPP Release 18, which shipped 5G-Advanced, delivers URLLC at sub-millisecond radio interface latency with 99.999% reliability. Release 19, now in flight, layers on robotics and XR service profiles, AI/ML primitives inside the RAN, and time synchronisation independent of GNSS — the precise capability set you need to schedule a deterministic VLA inference call from a moving humanoid. Private 5G is already live in serious industrial deployments: Mercedes Sindelfingen Factory 56, BMW Regensburg, Siemens Amberg, Samsung’s campuses. By the time 6G ULL targets sub-0.1-millisecond air-interface latency, the architectural premise will be obvious in hindsight.
Here is the part nobody quite says out loud: a current-generation on-robot VLA inference call is already 50–200 milliseconds end-to-end. Whatever URLLC budget we negotiate — even a generous 5 milliseconds round-trip on the air interface plus 20 milliseconds of edge compute — is far below the existing inference latency floor. The network is not the latency bottleneck. The model is. Which means moving inference to a network edge does not degrade latency; it simply removes the appliance constraint.
Fleet tier: where Physical AI actually learns
Learn happens above the network tier, in a continuous-training plane that no humanoid OEM is yet running at industrial scale outside of Tesla’s captive Optimus pipeline. This is where the sim-to-real-to-sim flywheel lives. Where driver — in this case, operator — interventions become labelled training signal. Where shadow-mode evaluation pits new policies against production policies. Where model weights are versioned, audited, and rolled out with the same OTA discipline the SDV world has spent a decade learning to do safely. And critically, where data residency, encryption-at-rest, regional compliance, and customer-owned-weight isolation become first-class architectural concerns rather than afterthoughts.
The sovereignty layer, which nobody is selling
Here is the part of the thesis that turns a clever architecture into a market position. Read the transcript that prompted this article again, specifically the Wolfpack section. China publicly announced a networked autonomous combat system of robot dogs and drones — scout, logistics, and armed-assault roles — with multi-modal control and a coordination layer engineered for GPS-denied operation. The platform is impressive engineering. It is also, for an entire half of the addressable global market, completely unshippable.
No NATO defence integrator can run a fleet whose inference plane terminates in Beijing. No US hospital network can run an embodied AI under HIPAA whose model weights are versioned on a non-sovereign cloud. No EU pharmaceutical line can run a humanoid whose data flywheel crosses a regional residency boundary. No Bundeswehr unit, no UK MoD operator, no Korean chaebol with a NIS-2 footprint, no Australian critical infrastructure operator can deploy a robot whose data plane is more sensitive than its actuator plane and whose telemetry routes outside their jurisdiction.
A robot is a sensor that goes everywhere. Its data plane is far more sensitive than its actuator plane, and almost nobody is architecting for that.
The sovereign fleet inference plane is, today, an unshipped product. It does not exist as a commercial category. The Chinese OEMs cannot ship it on their current architecture. The Western OEMs have not architected toward it yet. The hyperscalers are circling but their default deployment models are not sovereign-by-construction. The opportunity space is enormous and surprisingly empty. A correctly disaggregated thin-robot stack — with a regional inference plane, customer-owned weights, encrypted backhaul over private 5G-Advanced, and a learning tier inside the customer’s data sovereignty boundary — is exactly the architecture the regulated half of the world needs and exactly the architecture nobody is currently selling.
The cost re-architecture, applied
The thin robot is not just a strategic story. It is a unit-economics story that the memory super-cycle has just made urgent. Pull the Hyundai Lesson forward and apply it. Today’s reference humanoid BOM is roughly sixty percent actuators, fifteen to twenty percent compute and memory and battery, ten to fifteen percent sensors, and the rest chassis and harness. With LPDDR5X at five to six times its 2024 price and on-robot VLA footprints scaling, the compute-and-memory line item is on its way to twenty-five or thirty percent. That movement either eats the gross margin or kills the price point. The Unitree R1 at $4,370 today is exactly the kind of consumer-aspirational price that does not survive a 250% memory line-item shock.
A thin-robot BOM solves this directly. Cut the on-robot inference SoC to a quarter or less of its current footprint. Cut the on-robot RAM from thirty-two or sixty-four gigabytes down to eight, sometimes four. Move the rest of the brain to a fleet-amortised inference plane that the customer pays for monthly, on a per-robot or per-operator basis. The unit price drops. The BOM becomes resilient to memory volatility. Upgrades to the brain no longer require recall-class hardware refreshes. And the inference plane revenue line — fleet-as-a-service, sovereign-grade — starts to look more like the gross-margin profile of an enterprise SaaS than that of a consumer appliance.
What the industry still has not built
Pull the threads together and the gap analysis is uncomfortable. The pieces exist. The architecture does not. This is the missing layer:
|
GAP ANALYSIS — the Physical AI
fleet plane nobody has shipped |
|
→ A
sovereign fleet inference plane — cross-vendor, OEM-agnostic, hosted inside
customer or regional sovereignty boundaries — capable of serving multi-modal
VLA inference to fleets of thin robots over private 5G-Advanced. → VLA
model partitioning frameworks that split the model graph cleanly between
on-robot safety inference and network-tier reasoning, with deterministic
latency budgets and graceful fail-operational behaviour when the link drops. → Robotics
service profiles inside 3GPP Release 19 private-5G deployments — the precise
feature set the standards body is now ratifying, and which almost no humanoid
OEM is engineering against. → Mixed-criticality
compute on the robot itself, separating ASIL-D safety reflex compute from
best-effort microservices on the same SoC family — a problem the automotive
E/E architecture community has solved, and the humanoid community has not yet
inherited. → Encrypted,
regionally compliant fleet learning pipelines with customer-owned weights,
audit trails, and OTA discipline good enough to pass medical-device, defence,
and pharma regulatory review. → Supply-chain
integration of compute and memory at the same level of strategic seriousness
that East Asian humanoid OEMs have brought to actuators. The Hyundai Lesson,
extended one layer up the stack. |
The Hyundai Lesson, extended
The original Hyundai Lesson said: actuators are sixty percent of BOM, and the OEM that controls the joint supply chain controls the cost curve of the humanoid market. That argument is still correct. It is also no longer sufficient. The next strategic chokepoint is forming visibly: compute and memory, under structural super-cycle pressure, with no Western supply-chain integration that resembles what East Asia has built around joint motors. The OEM that wins the next decade will integrate two supply chains, not one. The OEM that goes thin will sidestep the second chokepoint entirely by routing it through a fleet service — turning a BOM problem into a service-revenue line.
If your autonomy stack works in Bengaluru, it works anywhere. If your robot can’t ask the network for help, it isn’t a fleet — it’s an island.
The GPT-2 moment, reframed
Karol Hausman is right that we are at the GPT-2 moment of robotics. The generalist policies are real. The pretraining recipes are converging. The data flywheel is starting to spin. π0 and π0.5 are foundation models in the meaningful sense. But the GPT-3 moment in language models was not about a better model on a bigger box. It was about an API. It was about decoupling the brain from the appliance, putting it behind a serving infrastructure, and letting a thousand applications consume it without each one having to host the weights. Until Physical AI has its serving infrastructure — sovereign, deterministic, latency-bounded, regionally compliant, delivered over private 5G-Advanced today and 6G ULL tomorrow — the robot will remain an appliance carrying its own brain around in its chest cavity, and the unit economics will be hostage to whichever year the DRAM cycle decides to turn.
The next phase of Physical AI does not belong to whichever team can cram the biggest VLA model into a humanoid’s chest. It belongs to whichever team is the first to ship the fleet inference plane that makes the chest cavity unnecessary.
What we will write next
In the next Lens, I will look at how ISO 25785-1 — the upcoming functional-safety standard for humanoid robotics — codifies many of the same mixed-criticality and learning-in-the-field principles into a regulatory framework, and what that means for OEMs whose architectures cannot meet it. After that, the sovereign defence robotics piece: what a NATO-deployable thin humanoid stack actually looks like, why China’s Wolfpack is the cautionary tale and not the template, and where the European primes still have an opening to lead. Both pieces build directly on the architecture sketched here. The thin robot is not the destination. It is the first honest layer of an architectural stack that the industry has not yet drawn.



